地理空間属性でソートするとテーブルサイズがめちゃくちゃ減る
今回は、地理空間データにおけるSnowflakeのテーブル最適化について紹介したいと思います。
目次
テーブル最適化するに至った経緯
業務で扱うテーブルは、サイズが大きいもので10~20TBで、WORM (Write Once Read Many)ライクなものが多いです。これらのテーブルを利用する際の課題が
- クエリのスキャン効率が良くない
- ストレージサイズコストがまあまあ高くなる
でした。
テーブルを最適化すれば、クエリパフォーマンス向上やストレージサイズの削減につながり、その効果がずっと続きます。これがテーブル最適化を実行するに至った経緯です。
地理空間属性でソートするだけで効果が得られる?
試行錯誤した結果、地理空間データの場合は地理空間属性でソートすることで
- クエリパフォーマンスの向上
- テーブルサイズの削減
の効果が得られることが分かりました。ソートによってデータがクラスタ化されるためだと考えています。
📈 手動ソートによるクエリパフォーマンスの向上
ちなみにデータクラスタ化する方法として、手動ソートは割と有名な最適化の手法ですよね。 以下の記事がわかりやすいです。
🗺️ 地理空間データの特性
ソートしただけでテーブルサイズがめちゃくちゃ減ることに驚きました。テーブルによっては半分以上も減ることがわかっています。
地理空間データには空間的な連続性や類似性があります(= Tobler’s first law of geography)。これについては別の記事で説明したいと思います。
なぜ減るのかの理由については、おそらく地理空間属性のカラムでソートすることでデータ全体がクラスタ化され、データ圧縮率の向上につながったというふうに考えてます。
今回はこれを実際にオープンデータで検証していきます!
データ検証してみる
🗄️ 利用データ
国土交通省が提供している土地利用細分メッシュデータを利用します。このデータには100mメッシュコードごとに土地の利用区分データが格納されています。
ダウンロードする条件は以下の通りです。
- 対象範囲:日本全国
- 測地系:世界測地系
- 年度:2021年(令和3年)
全てダウンロードすると計176ファイルあります。
❄️ Snowflakeへロード
Snowflake上にデータをロードし、以下の手順に沿って検証していきたいと思います。
- ダウンロードしたデータをParquet形式に変換
- 内部ステージを作成
- Snowsight経由でファイルをロード
- テーブル作成
- 空間に関する属性のカラムでソート
1. ダウンロードしたデータをParquet形式に変換
利用するデータはGeojson形式で保存されているのでParquet形式に変換します。シェルスクリプトで変換処理を行いました。
ディレクトリ構成は以下の通りです。
./
├── geojson # GeoJsonファイル用フォルダ
├── parquet # Parquetファイル用フォルダ
├── process.sh # 変換用スクリプト
└── zip # ソースデータ用フォルダ
├── L03-b-21_3036-jgd2011_GML.zip
├── L03-b-21_3622-jgd2011_GML.zip
├── L03-b-21_3623-jgd2011_GML.zip
...
└── L03-b-21_5029-jgd2011_GML.zipprocess.shの中身は以下の通りです。
#!/bin/bash
# ディレクトリ定義
ZIP_DIR="./zip"
GEOJSON_DIR="./geojson"
PARQUET_DIR="./parquet"
TMP_DIR="./tmp_geojson"
# 一時フォルダの作成
mkdir -p "$TMP_DIR"
mkdir -p "$GEOJSON_DIR"
# zipファイルをすべて処理
for zipfile in "$ZIP_DIR"/*.zip; do
echo "Processing $zipfile..."
unzip -o "$zipfile" -d "$TMP_DIR"
done
# geojsonファイルを移動(重複チェックあり)
find "$TMP_DIR" -name "*.geojson" | while read -r geojson; do
filename=$(basename "$geojson")
# UTF-8エンコーディングに強制変換(オプション:iconvを使う場合)
utf8_file="$GEOJSON_DIR/$filename"
iconv -f SHIFT_JIS -t UTF-8 "$geojson" -o "$utf8_file" 2>/dev/null || cp "$geojson" "$utf8_file"
done
# 一時フォルダ削除
rm -rf "$TMP_DIR"
# Parquet変換(GDAL使用)
for geojson_file in "$GEOJSON_DIR"/*.geojson; do
base_name=$(basename "$geojson_file" .geojson)
parquet_file="$PARQUET_DIR/${base_name}.parquet"
echo "Converting $geojson_file to $parquet_file..."
ogr2ogr -f Parquet -lco GEOMETRY_ENCODING=WKT "$parquet_file" "$geojson_file"
done
echo "✅ 完了:全てのGeoJSONファイルをParquet形式に変換しました。"
Parquetファイルに出力する際に、-lcoオプションでgeometry情報をWKT形式で保存するように指定しています。
これはogr2ogrでは出力がGeoParquet形式で出力されるんですが、SnowflakeではGeoParquet形式に対応していないからです。(Snowflakeも早くGeoParquetに対応してほしいですね。。)
2. 内部ステージを作成
create or replace stage stg_landuse_subdivision_mesh
directory = (enable = true)
file_format = (type = parquet)
;3. Snowsight経由でファイルをロード
Parquetファイルを内部ステージにSnowsight経由でロードしていきます。
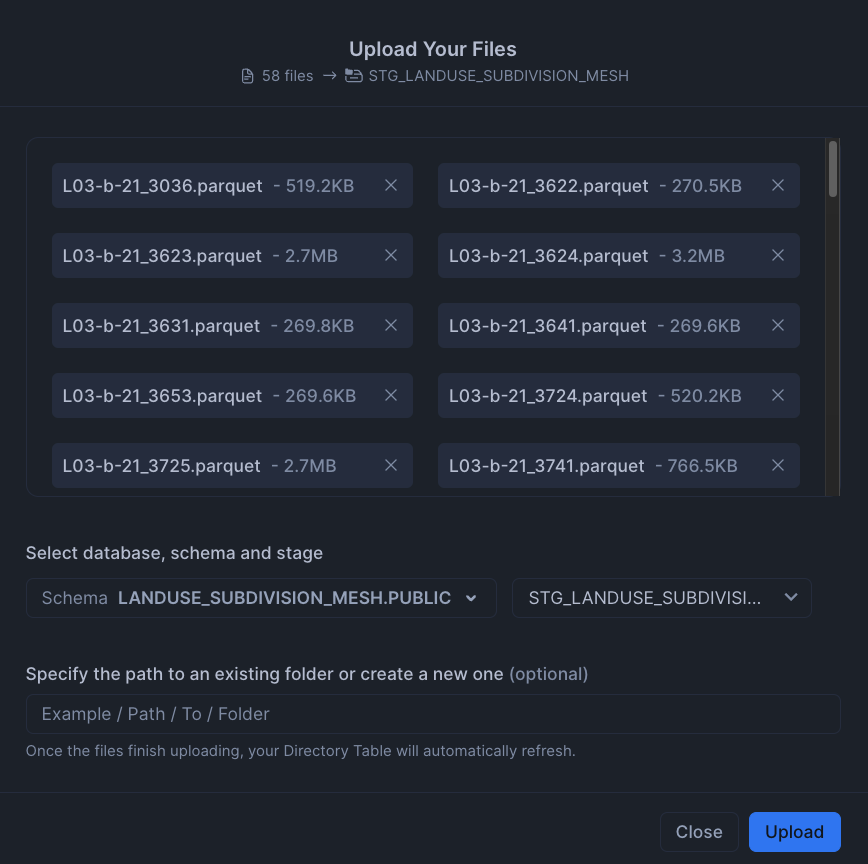
4. テーブル作成
ランダムにデータをインサートする。比較のためにデータをランダムに格納したテーブルを作ります。
create or replace table t_landuse_subdivision_mesh
as
select
$1:"細分メッシュコード"::STRING as mesh100m_code,
$1:"土地利用種別"::STRING as landuse_type,
$1:"衛星写真撮影年月日"::STRING as capture_date,
st_geographyfromwkt($1:geometry) as geom
from @stg_landuse_subdivision_mesh
order by random()
;5. 空間に関する属性のカラムでソート
create or replace table t_landuse_subdivision_mesh_sorted
as
select *
from t_landuse_subdivision_mesh
order by mesh100m_code
;ソート前後の比較
ソート前後のテーブルの統計量、クラスタリング情報は以下のようになりました。
| 項目 | ソート前 | ソート後 |
|---|---|---|
| テーブルサイズ | 7.2GB | 1.6GB |
| total_partition_count | 431 | 104 |
| total_constant_partition_count | 0 | 0 |
| average_overlaps | 430 | 1.9808 |
| average_depth | 431 | 2 |
手動でのソートにより、データがクラスタリングされ、テーブルサイズが従来に比べて77%も減っていることがわかります。
扱う地理空間データサイズが大きくなるほど、ソートで得られる効果も大きくなると思います。
最後に
ソートするだけでテーブルサイズが減ることが検証結果からわかりました。
Snowflakeの詳細な圧縮技術に関しては内部情報なので公開はされてなさそうでした。ですが、どんな技術を使っているのかは気になりますね。
もしこの記事が誰かの参考になれば嬉しいです。それではまた!